ادغام تصاویر با روش پواسون _ لاپلاسین در متلب
ادغام تصاویر با روش پواسون _ لاپلاسین در متلب : پروژه متلب
پروژه متلب :
ماتريسي که در صفحه قبل مشاهده مي کنيد يک تصوير به فرض سياو و سفيد است ( رنگ هايي که در تصوير مشاهده مي کنيد براي جدا کردن آبجکت ها است ) در خانه هايي که آبجکتي وجود ندارد مقدار صفر و در پيکسل هايي که آبجکت وجود دارد عدد يک وجود دارد .
از سطر اول شروع مي کنيم و آنقدر در سطر حرکت مي کنيم تا به اولين پيکسلي که حاوي مقدار ۱ است برسيم , اين پيکسل را به عنوان اولين آبجکت در نظر مي گيريم . کار را ادامه مي دهيم در سطر بعد اولين مقدار ۱ که رسيديم همسايه هاي ۸ گانه آنرا نگاه مي کنيم . اگر بين پيکسلي که قبلا نشانه گذاري کرده بوديم و پيکسلي که الان به آن رسيديم مسيري وجود داشت , اين ۲ پيکسل هر دو از يک آبجکت هستند , پس به اين پيکسل نيز برچسب همان پيکسل قبلي را مي زنيم . کار ادامه پيدا مي کند تا جايي که به پيکسلي ميرسيم که در شکل مشخص شده است که متعلق به آبجکت يک است ولي در همسايگي آن پيکسل برچسب گذاري نشده است .
بدون در نظر گرفتن اين موضوع برچسب جديدي را به آن مي زنيم . کار را به همين صورت ادامه ميدهيم ته به پايان برسيم .
پروژه متلب : نکته قابل توجه اينجاست که آبجکت هايي که با ۲ برچسب مشخص شده اند در جايي اين ۲ پيکسل به هم ميرسند . در بار دوم که ماتريس تصوير را رفرش مي کنيم به محل تلاقي برچسب ها که رسيديم مقدار برچسب کوچکتر را در برچسب هاي بزرگتر قرار مي دهيم . حال با ۲ بار رفرش کردن تصوير با فرض سياه و سفيد بودن تصوير مي توان تمامي آبجکت ها را مشخص و جدا کرد .
- براي يافتن لبه ها به شکل زير عمل مي کنيم :
- براي لبه هاي افقي از ستون اول به صورت عمودي شروع به حرکت مي کنيم و هر پيکسل را با پيکسل قبل از خودش مقايسه مي کنيم اگر تفاوت آنها از عدد مشخصي بيشتر باشد آنجا لبه است . در غيراين صورت به آن کاري نداريم .
- يافتن لبه هاي عمودي هم به همين صورت است منتها به صورت افقي شروع به حرکت مي کنيم .
- لبه هاي مورب ميشه گفت ترکيبي از اين ۲ لبه اند به اين صورت که جذر جمع مختصات هر پيکسل بايد از عددي مشخص بيشتر باشد در غير اين صورت لبه نيست .
- شناسايي الگو ( ادامه … )
شناسايي الگو يکی از شاخه هاي هوش مصنوعي است كه با طبقه بندي (كلاسه بندي) و توصيف مشاهدات سروكار دارد. . شناسايي الگو به ما كمك مي كند تا داده ها (الگوها) را با تكيه بر دانش قبلي يا اطلاعات آماري استخراج شده از الگوها، طبقه بندي نماييم. الگوهايي كه مي بايست كلاسه بندي شوند، معمولا گروهي از سنجش ها يا اهداف هستند كه مجموعه نقاطي را در يك فضاي چند بعدي مناسب تعريف مي نمايند.
- كاربردهاي بازشناسي الگو
پروژه متلب : بازشناسي الگو در بسياري از زمينه ها نقش كاربردي دارد . بازشناسي حروف، بازشناسي نويسنده، تصديق امضاء، طبقه بندي اثر انگشت و بازشناسي گفتار نمونه هايي از اين كاربردها هستند. شناسايي الگو براي تحليل داد ه هاي پزشكي نيز بكار گرفته شده است.
- كاربردهاي بازشناسي الگو
براي مثال تفسيرالكتروكارديوگرام، تحليل تصاوير اشعه X و طبقه بندي كروموزم ها را مي توان نام برد.
نمونه هاي ديگري از اين كاربردها شامل طبقه بندي مناطق زراعي، مطالعه آلودگي آب ها، آشكار كردن منابع زيرزميني و پيش بيني آب و هواست. در اين نوع كاربردها ، تصاوير ارسال شده از ماهواره و تصاوير هوايي به كمك روش هاي بازشناسي الگو تفسير مي شوند. بازرسي تصويري و بازشناسي قطعات ماشيني، از كاربردهاي صنعتي شناسايي الگو هستند. تحليل بافت ، آشكارسازي هدف در سيگنال هاي برگشتي رادار يا سونار ، طبقه بندي امواج زلزله و تشخيص ذرات شيميائي كاربردهاي ديگري از بازشناسي الگو مي باشند.
- مقدمه اي بر پردازش متن
پروژه متلب : افزايش روزافزون توليد اطلاعات كه غالباً به صورت مواد چاپي به بازار عرضه ميگردد و ضرورت دسترسي سريع و آسان به داده هاي موجود از يك سو، و حضور فراگير رايانه در عرصه هاي مختلف زندگي از سوي ديگر، متخصصان فناوري اطلاعات را بر آن داشته كه همواره در پي يافتن راهكار مناسب براي گردآوري و پردازش اطلاعات به كمك رايانه باشند. تبديل اطلاعات متني با مشخصه هاي متفاوت به مستندات متني استاندارد کامپيوتري يکي از راهکارهاي افزايش بازدهي فناوري اطلاعات است.
مزيت متن واقعي به ساير اشکال يک مستند بطور خلاصه عبارتند از:
- متن، قابل ويرايش و جستجو است و به آساني مي توان آنرا پردازش کرد. امکان جستجوي عبارات در يک متن حجيم، امتياز بزرگي است.
- حجم متن معمولا بسيار کمتر از حجم تصوير مشابه است.
- به متن ميتوان بسادگي توضيح، فرالينک، و امکانات رسانه مرکب افزود.
پروژه متلب : اقدامات اوليه در زمينه OCR، بر متون چاپي يا مجموعه كوچكي از حروف و نمادهاي دستنويس كه براحتي قابل تشخيص بودند متمركز گرديده بود که عمدتاً از روش تطبيق قالب استفاده مينمودند به اين صورت كه در آن تصوير ورودي با مجموعه بزرگي از تصاوير حروف مورد مقايسه قرار ميگرفت . در اين دوره، تحقيقات موفق اما محدود شده (منظور از محدود شده، مفروض دانستن شرايط و پيشفرضهاي خاص براي كاراكترهاي ورودي است)، بيشتر بر روي حروف و اعداد لاتين انجام گرفت. با اين حال مطالعات چندي نيز بر روي حروف ژاپني، چيني، عبري، هندي، سيريليكي، يوناني و عربي در هر دو زمينه حروف چاپي و دستنويس آغاز گرديد . مطالعات صورت گرفته تا قبل از سال ۱۹۸۰ بدليل فقدان سختافزارهاي قدرتمند و دستگاههاي ورودي مناسب با مشكل همراه بودند. اما از دهه ۱۹۸۰ به بعد بواسطه رشد انفجارگونه فناوري اطلاعات، وضعيت بسيار مناسبي براي تحقيقات مختلف از جمله بازشناسي حروف فراهم گرديد .
پروژه متلب : در اين مقطع زماني بود كه با تكوين ابزارها و تكنيكهاي پردازشي جديد، پيشرفت واقعي در سيستمهاي OCR محقق گرديد. در اوايل دهه ۹۰، روشهاي پردازش تصوير و بازشناسي الگو با تكنيكهاي كارآمد هوش مصنوعي ادغام گشتند. محققان، الگوريتمهاي پيچيدهاي را در بازشناسي حروف ابداع نمودند كه قادر بودند دادههاي ورودي با تفكيكپذيري بالا را دريافت كنند و در مرحله پيادهسازي، محاسبات بسيار زيادي را بر روي دادهها انجام دهند. امروزه علاوه بر وجود رايانههاي قدرتمندتر و تجهيزات الكترونيكي دقيقتر مانند اسكنرها، دوربينها و صفحات رقميكننده، استفاده از تكنيكهاي پردازشي مدرن و توانمند همچون شبكههاي عصبي ، مدلهاي ماركوف پنهان ، منطق فازي، و مدلهاي پردازش زبان طبيعي امكانپذير گشته است .
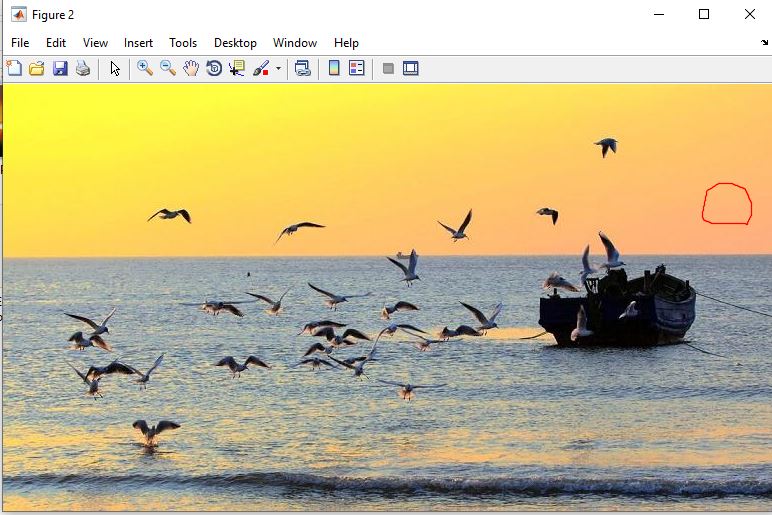
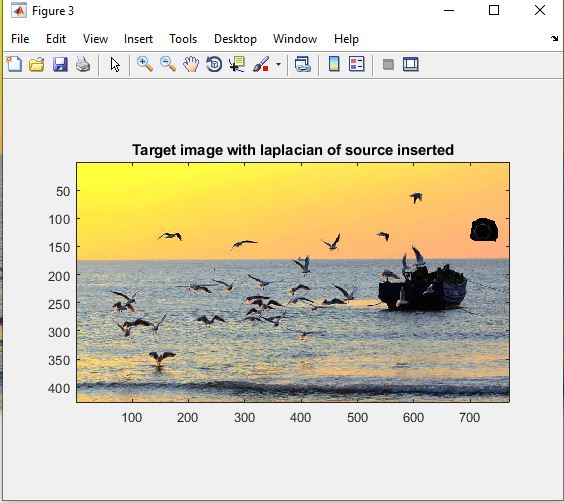
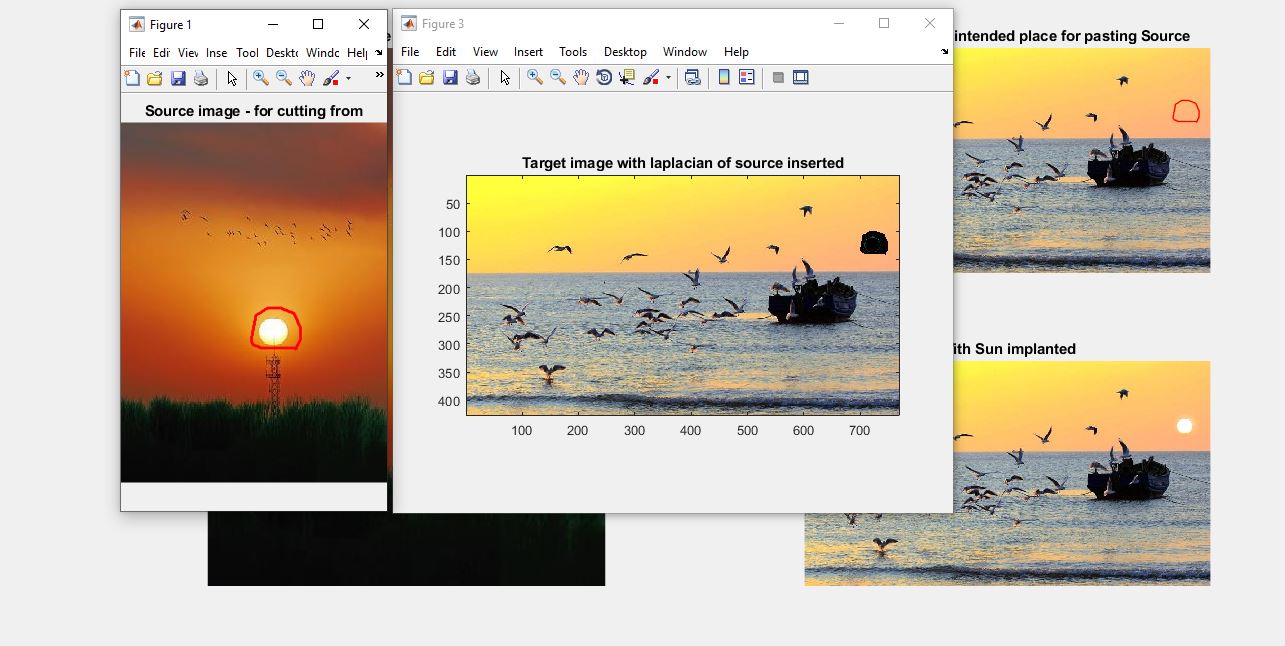
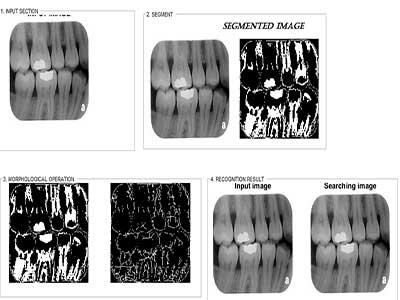
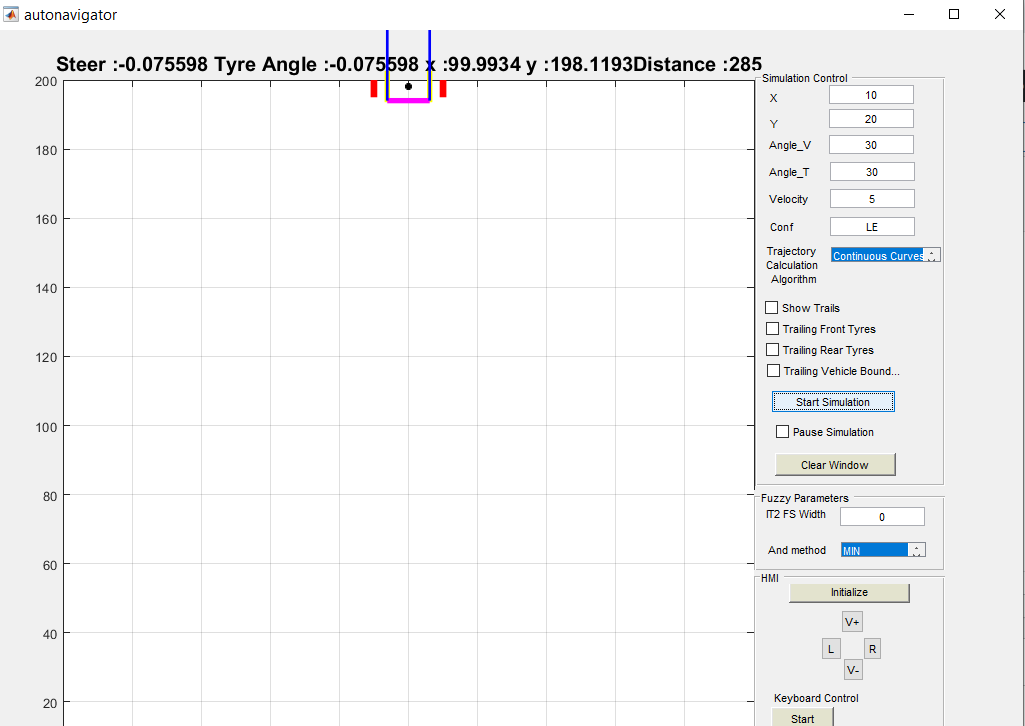
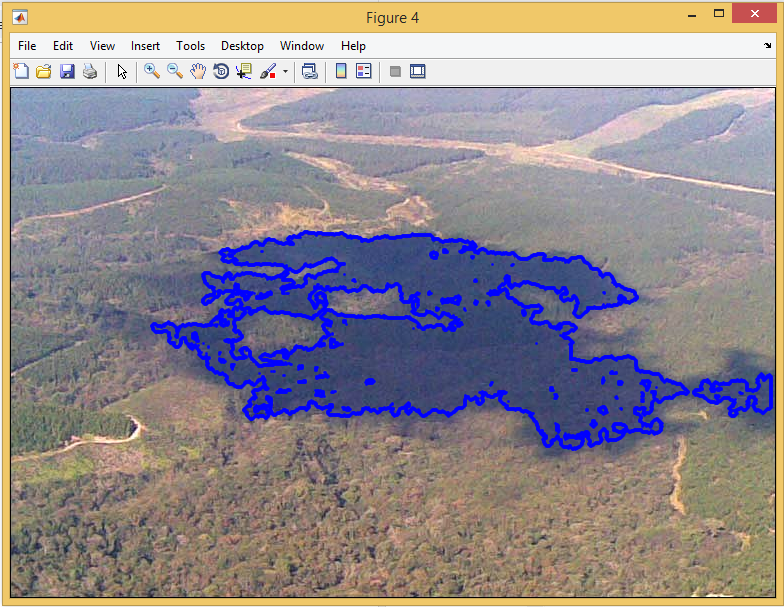
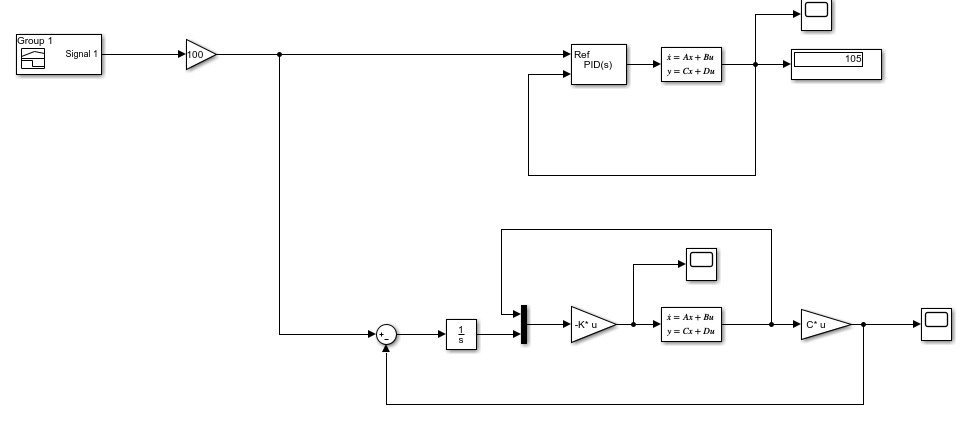
خروجی متلب :


لطفاً براي ارسال دیدگاه، ابتدا وارد حساب كاربري خود بشويد