تشخیص پلاک خودرو ایرانی با استفاده از روش مورفولوژِی (ریخت شناسی) در متلب
تشخیص پلاک خودرو با استفاده از روش مورفولوژِی (ریخت شناسی) در متلب :پروژه متلب
پروژه متلب تشخیص پلاک خودرو از جمله وظایف پراستفاده پردازش تصویر و یادگیری ماشین در دنیای واقعی است که به همین دلیل با چالشها و موانع بسیاری همراه است، بهعلاوه این وظیفه، کاربردهای زیادی در مراکز و سازمانها بخصوص سازمانهای راهنمایی و رانندگی، پارکینگها و مراکز خرید دارد.
هدف نهایی این پروژه ایجاد و آموزش مدل یادگیری عمیقی بود که بتواند پس از تشخیص پلاکهای موجود در تصاویر گرفته شده، شماره پلاکهای مربوطه را مشخص کرده و نمایش دهد.
چالشها
پروژه متلب از چالشهای این پروژه میتوان به نبود دیتاست پلاکهای فارسی خودرو چه تصاویر خودرو به همراه پلاک و چه تصاویر پلاکهای برش دادهشده، مشخص نبودن قطعی فونت مورد استفاده در پلاکهای فارسی که کار تولید پلاکهای مصنوعی را دشوارتر میکرد اشاره کرد.
پیادهسازی
پروژه متلب برای این پروژه دو مدل آموزش داده شدند، یک مدل تشخیص اشیاء (Object Detection) برای تشخیص موقعیت پلاکها در تصویر و یک مدل تشخیص کاراکتر (OCR) برای تشخیص شماره پلاکهای تشخیص داده شده که در ادامه بررسی خواهند شد.
کدها و دیگر فایلهای مورد استفاده در پیادهسازی و انجام این پروژه را میتوانید در ریپازیتوری این پروژه در گیتهاب مشاهده کنید.
مدل تشخیص اشیاء (Object Detection)
پروژه متلب وظیفه این مدل، تشخیص موقعیت پلاکهای موجود در تصویر و برگرداندن تصویر برش دادهشده آنهاست. برای پیادهسازی آن از یک شبکه YOLO ورژن ۳ نسخه سریعتر و کمحجمتر Tiny استفاده شده است.
پروژه متلب برای تولید دیتاست این مدل، تصاویر پلاکهای واقعی (که از دیتاستی که در این ریپازیتوری قرار داده شده استفاده شد) به صورت رندوم برروی تصاویر پسزمینهای شامل جاده و ماشین قرار گرفتند تا تصاویری مانند زیر تولید شوند:

این تصاویر به همراه موقعیت پلاکها به شبکه تغذیه شدند تا مدل آموزش یابد.
مدل تشخیص کاراکتر (OCR)

وظیفه این مدل، تشخیص شماره پلاک از روی تصویر آن است که برای پیادهسازی آن از ترکیب مدلهای CNN، LSTM بههمراه تابع هزینه CTC استفاده شد. برای این بخش از مدل از پیش آموزش داده شده ای که در این ریپازیتوری قابل دسترسی است استفاده شد.
از آنجایی که مدلهای بازگشتی LSTM نیاز به دیتاست فراوان برای آموزش دارند و دیتاست مناسبی از پلاکهای فارسی خودرو موجود نبود اقدام به تولید پلاکهای مصنوعی کردیم تا بتوانیم مدل بازگشتی را به خوبی آموزش دهیم.
تولید پلاک مصنوعی
پروژه متلب همانطورکه گفته شد، برای تولید دیتاست شبکه بازگشتی اقدام به تولید دیتاستی از پلاکهای مصنوعی کردیم. برای اینکار لازم بود تا فونت مورد استفاده در پلاکهای فارسی را بشناسیم، انواع مختلف قالبهای مورد استفاده در پلاکهای مختلف را بدست آوریم، با چیندن اعداد و حروف برروی قالبها پلاکهارا تولید کنیم، سپس قالبها را به صورتهای مختلف تغییر شکل دهیم تا مطابق شرایط طبیعی باشند و همچنین به آنها نویز اضافه کنیم.
فونت

پروژه متلب ابتدا لازم بود تا فونت مورد استفاده در پلاکهای خودرو را بشناسیم، بدین منظور پس از بررسی فونتهای مختلف و پرسوجو، فونتهای ترافیک، رویا و ترکیبهایی از فونتهای دیگر را تست کردیم؛ در نهایت، فونت رویا بولد فونتی بود که ما برای تولید پلاک انتخاب کردیم. پس از مشخص شدن فونت میبایست گلیفها (کاراکتر حروف و اعداد) فونت را استخراج میکردیم تا بتوانیم با آنها پلاکهای مصنوعی بسازیم.
برای استخراج گلیفها از نرمافزار FontForge استفاده کردیم؛ همراه با نصب این نرمافزار یک مفسر پایتون که کتابخانه کار با این ابزار توسط پایتون نیز به صورت داخلی در آن موجود است نیز نصب میشود که ffpython نام دارد و در پوشه نرمافزار پس از نصب موجود است.

پروژه متلب با استخراج گلیفهای یک فونت تمامی کاراکترهای آن فونت به صورت فایلی png که پسزمینه سفیدی دارد ذخیره میشوند، که نیاز بود گلیفهای بیاستفاده پاک شده و پسزمینه تصاویر نیز حذف شوند. همچنین گلیفها باید به نامی با مفهوم و همطول -در بررسیهایی که کردیم بهاین نتیجه رسیدیم که این مورد در آموزش بهتر شبکه OCR موثر است]- تغییرنام داده میشدند چراکه به صورت پیشفرض نام آنها کاراکتر unicode آنها بود. بنابراین برای نامگذاری آنها، بدین صورت عمل کردیم که هر گلیف به صورت دو حرف نمایش داده شود که حرف اول کاراکتر آن و حرف دوم نشان دهنده صورت کاراکتر است چراکه در زبان فارسی بعضی کاراکترها مانند «ت» یا «س» به چند صورت مانند «ط» و «ص» نوشته میشوند.
بنابراین برای اتوماتیک سازی این فرایند اسکریپتی به نام extract_glyphs.py نوشته شد که از پوشه فونتها فونتها را خوانده و توسط کتابخانه fontforge موجود در مفسر ffpython گلیفها را استخراج کرده و توسط فایل csv موجود در دایرکتوری فونتها که مشخص میکند کدام کاراکترها باید نگهداشته شوند و همچنین به چه نامی باید تغییرنام داده شوند فایل تصاویر استخراج شده از گلیفها را مرتب میکند.
سپس، لازم بود این تصاویر پردازش شوند و پسزمینه آنها و سپس حاشیهها حذف شده و به سایزهای مورد استفاده در پلاک تبدیل شوند. بدین منظور اسکریپت دیگری به نام process_glyphs.py نوشته شد.
پروژه متلب برای اینکار از کتابخانه PythonMagick استفاده کردیم که درواقع یک پیادهسازی پایتونی برای کار با ابزار ImageMagick است [در اینجا در مورد Imagemagick بخوانید] که سرعت و راحتی استفاده از آن عاملهای اصلی استفاده از آن بود.
قالب

پروژه متلب پلاکها براساس نوع وسیلهای که به آن تعلق دارند قالبهای متفاوت با رنگها و گاها طرحهای متفاوتی دارند. برای تشخیص انوع مختلف پلاکها لازم بود پلاکهایی که تولید میکردیم از قالبهای مختلفی تشکیل شده باشند.
اعمال نویز

پروژه متلب در شرایط محیط واقعی پلاکها تمیز و بدون پوششهایی که میتواند مانعی برای تشخیص کاراکترهای پلاک باشد نیستند:

گدشته از تصاویر بالا عموما پلاکها نویزهایی مانند دوده، گل و لای، خط و خش دارند که تشخیص آنهارا کار دشواری میکند. برای به وجود آوردن شرایط مشابه، تصمیم گرفتیم در دیتاستی که میساختیم پلاکهایی با نویزهای مختلف نیز داشته باشیم.
بدین منظور با استفاده از براشهایی موجود در فتوشاپ سعی کردیم تصاویر بدون پسزمینهای از نویزها ایجاد کنیم که نتیجه کار ۸ نویز زیر بود:

سپس در زمان تولید پلاکها این نویزها را به تصاویر اعمال میکنیم که نتیجه کار پلاکی شبیه تصویر زیر باشد:

تغییر شکل

از آنجاییکه تصاویر گرفته شده از خودروها زاویههای مختلفی دارند، پلاکها با شکلها، اندازهها و پرسپکتیوهای مختلفی دیده میشوند. برای آنکه مدل قادر باشد شماره این پلاکها را نیز تشخیص دهد پلاکهای تولید شده را با استفاده از اعمال ماترسهای تغییرشکل مختلف برروی تصاویر تولید شده تغییر دادیم تا دیتاست حاوی این تصاویر نیز باشد. تصویر زیر نمونهای از تغییر شکلهای اعمال شده را نمایش میدهد (تغییر اندازه تصاویر مشخص نیست).
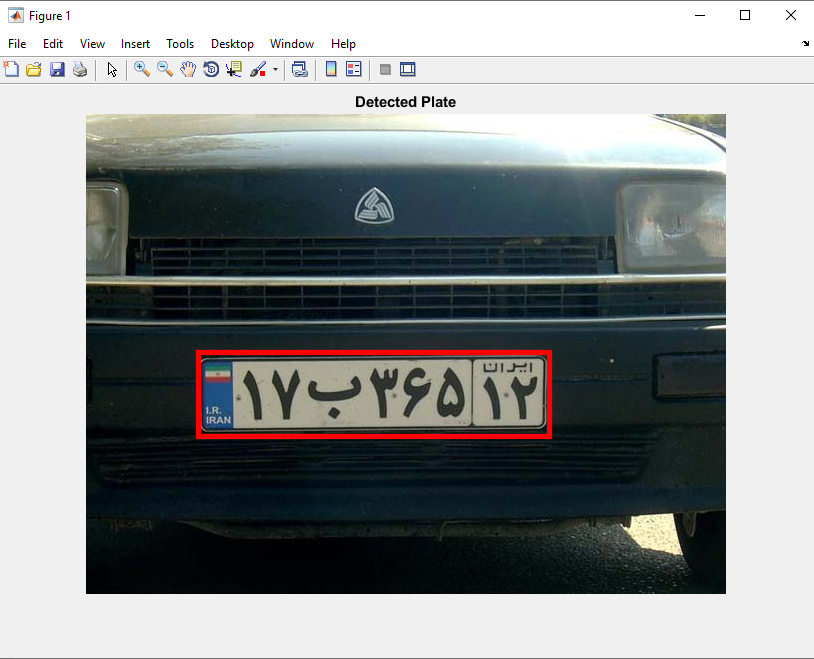
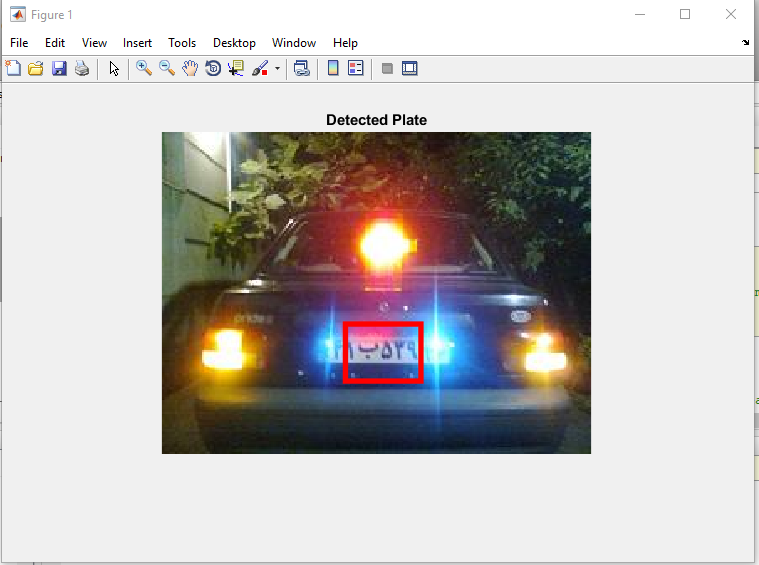
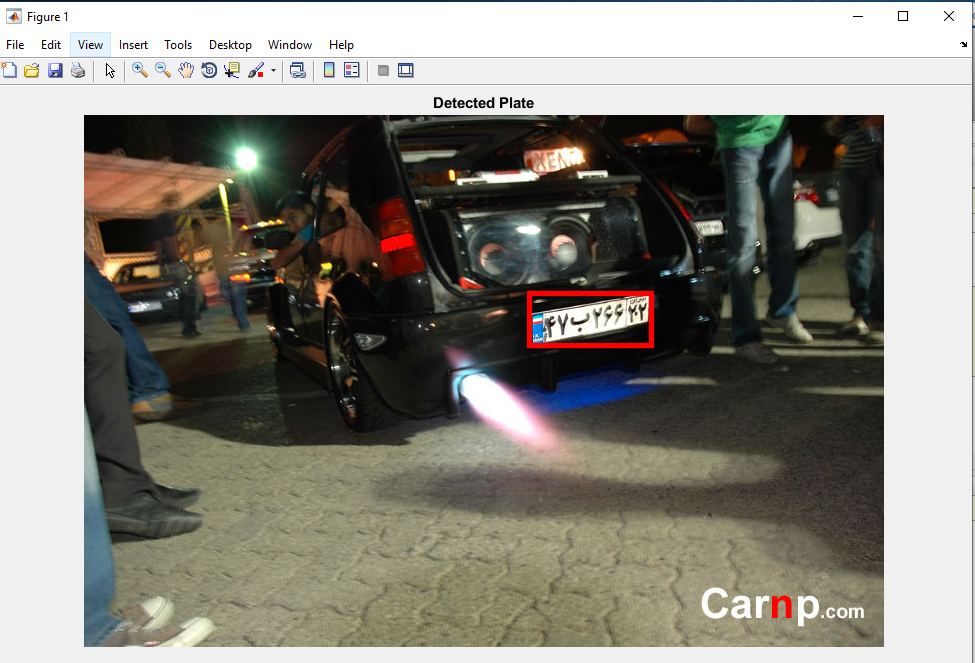
خروجی متلب :

لطفاً براي ارسال دیدگاه، ابتدا وارد حساب كاربري خود بشويد