پیاده سازی سیستم تطبیق الگو و یادگیری ماشین در متلب
پیاده سازی سیستم تطبیق الگو و یادگیری ماشین در متلب :انجام پروژه متلب
انجام پروژه متلب پروسه این پروژه بصورت زیر می باشد:
نسخه های نمایشی ارائه شده در وبینار به ترتیب عبارتند از:
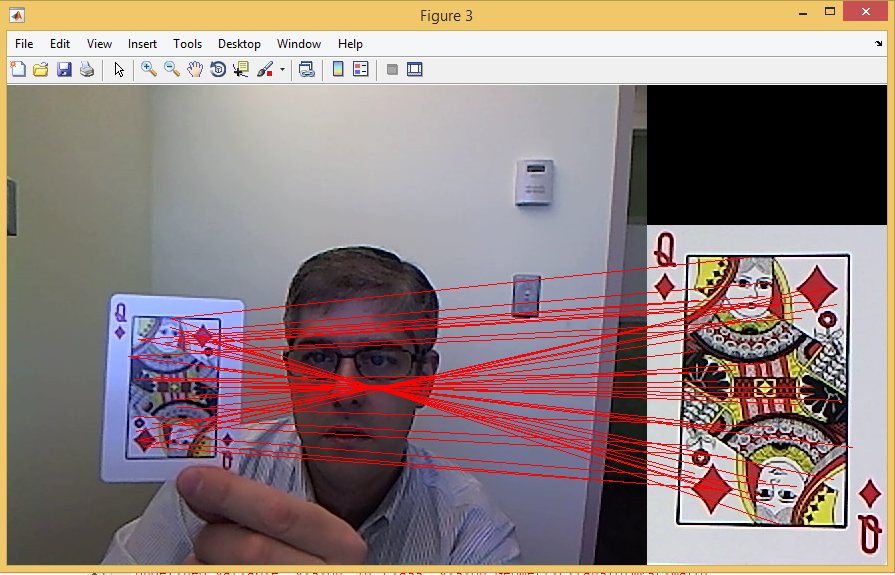
۱٫ ثبت نام مبتنی بر ویژگی (ImageRegistrationSURF3.m)
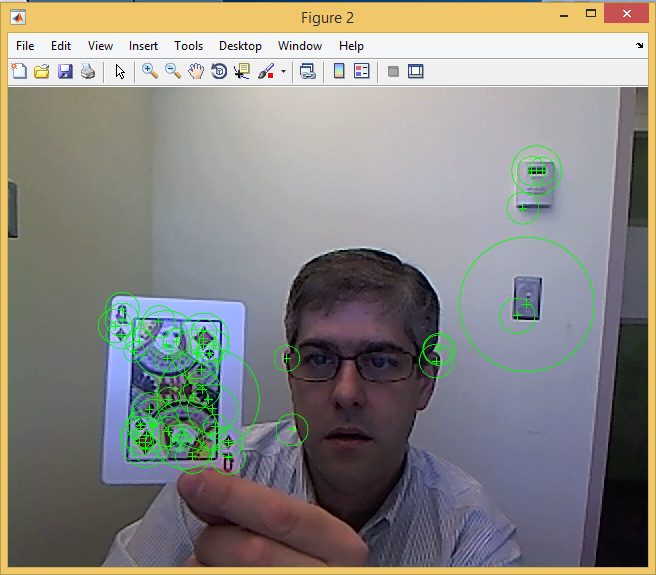
۲٫ تشخیص شی (MatchCard.m و ReplaceCard.m)
۳٫ تشخیص چهره (FaceDetection.m)
۴٫ پیگیری مبتنی بر هیستوگرام (FaceTracker.m)
انجام پروژه متلب به عنوان یکی از شاخههای وسیع و پرکاربرد هوش مصنوعی، یادگیری ماشین (Machine learning) به تنظیم و اکتشاف شیوهها و الگوریتمهایی میپردازد که بر اساس آنها رایانهها و سامانهها توانایی تعلٌم و یادگیری پیدا میکنند.
شما احتمالاً چندین بار در روز از یادگیری ماشین استفاده میکنید، حتی بدون آنکه بدانید. هر بار که شما یک جستجوی اینترنتی در گوگل یا بینگ انجام میدهید، یادگیری ماشینی انجام میشود چراکه نرمافزار یادگیری ماشینی آنها چگونگی رتبهبندی برای یک صفحه وب را درک کردهاست. هنگامی که فیسبوک یا برنامه عکس اپل دوستان و تصاویر شما را میشناسد، این هم یادگیری ماشین است. هر بار که ایمیل خود را چک میکنید انجام پروژه متلب و فیلتر هرزنامه شما را از داشتن مجدد هزاران هرزنامه خلاص میکند نیز به همین دلیل است که رایانهی شما آموختهاست که هرزنامه را از غیرهرزنامه تشخیص دهد. این همان یادگیری ماشین است. این علمی است که باعث میشود رایانهها بدون نیاز به یک برنامه صریح در مورد یک موضوع خاص یاد بگیرند.
یادگیری با نظارت
انجام پروژه متلب یادگیری تحت نظارت، یک روش عمومی در یادگیری ماشین است که در آن به یک سیستم، مجموعهای از جفتهای ورودی – خروجی ارائه شده و سیستم تلاش میکند تا تابعی از ورودی به خروجی را فرا گیرد. یادگیری تحت نظارت نیازمند تعدادی داده ورودی به منظور آموزش سیستم است. یادگیری تحت نظارت خود به دو دسته تقسیم میشود: رگرسیون و طبقهبندی. رگرسیون آن دسته از مسائل هستند که خروجی یک عدد پیوسته یا یک سری اعداد پیوسته هستند مانند پیشبینی قیمت خانه بر اساس اطلاعاتی مانند مساحت، تعداد اتاق خوابها، و غیره و دسته طبقهبندی به آن دسته از مسائل گفته میشود که خروجی یک عضو از یک مجموعه باشد مانند پیشبینی اینکه یک ایمیل هرزنامه هست یا خیر یا پیشبینی نوع بیماری یک فرد از میان ۱۰ بیماری. با این حال ردهای از مسائل وجود دارند که خروجی مناسب که یک سیستم یادگیری تحت نظارت نیازمند آن است، برای آنها موجود نیست. این نوع از مسائل چندان قابل جوابگویی با استفاده از یادگیری تحت نظارت نیستند. یادگیری تقویتی مدلی برای مسائلی از این قبیل فراهم میآورد. در یادگیری تقویتی، سیستم تلاش میکند تا تقابلات خود با یک محیط پویا را از طریق آزمون و خطا بهینه نماید. یادگیری تقویتی مسئلهای است که یک عامل که میبایست رفتار خود را از طریق تعاملات آزمون و خطا با یک محیط پویا فرا گیرد، با آن مواجه است. در یادگیری تقویتی هیچ نوع زوج ورودی- خروجی ارائه نمیشود. به جای آن، پس از اتخاذ یک عمل، حالت بعدی و پاداش بلافصل به عامل ارائه میشود. هدف اولیه برنامهریزی عاملها با استفاده از تنبیه و تشویق است بدون آنکه ذکری از چگونگی انجام وظیفه آنها شود.
یادگیری با نظارت آماری
انجام پروژه متلب در آماری احتمال خروجی بر حسب ورودی محاسبه میشود. اگر ورودی {\displaystyle x}باشد و خروجی {\displaystyle y}،{\displaystyle p(y|x)} از دادهها یادگرفته میشود، به عبارت دیگر یادگیری در واقع پیدا کردن تابع {\displaystyle p}است. دو روش کلی برای پیدا کردن تابع {\displaystyle p} وجود دارد: روش تولیدی (Generative) و روش تشخیصی (Discriminative). در روش تشخیصی {\displaystyle p(y|x)} مستقیماً یادگرفته میشود ولی در روش تولیدی ابتدا {\displaystyle p(y)} و {\displaystyle p(x|y)} از دادهها برآورد میشوند و بعد با استفاده از قانون بیز (Bayes) {\displaystyle p(y|x)} محاسبه میشود.






تعریف ریاضی یادگیری با نظارت
در یادگیری با نظارت، مثالهای آموزشی به صورت جفتهای ({\displaystyle x^{i},y^{i}}) که در آن هر نمونه به همراه بر چسب آن داده شدهاند و {\displaystyle i} اندیس هر مثال در مجموعه مثالهای آموزشی {\displaystyle D}است. هدف در این یادگیری بدست آوردن تابع {\displaystyle f} است که بتواند برای نمونههای ورودی دیده نشده {\displaystyle x}بر چسب مناسب را برگرداند یعنی {\displaystyle f(x)}را. نمونه و بر چسب هر دو میتوانند یک بردار باشند. اگر بر چسب یک عدد حقیقی باشد مسئله پیش روی ما «رگرسیون» (Regression) نامیده میشود. اگر بر چسب یک عدد صحیح باشد به مسئله «طبقهبندی» (Classification) گفته میشود.





یادگیری بی نظارت
یادگیری بی نظارت یا یادگیری بدون نظارت (انگلیسی: Unsupervised machine learning، در مقابل یادگیری بانظارت)، یکی از انواع یادگیری در یادگیری ماشینی است. اگر یادگیری بر روی دادههای بدون برچسب و برای یافتن الگوهای پنهان در این دادهها انجام شود، یادگیری، بدون نظارت خواهد بود. از انواع یادگیری بدون نظارت میتوان به الگوریتمهای خوشهبندی (Clustering)، تخصیص پنهان دیریکله (LDA) و جاسازی لغات (Word Embedding) اشاره کرد.
یادگیری تقویتی
انجام پروژه متلب هدف یادگیری تقویتی بخشی که از یادگیری ماشین است این است که چگونه عاملهای نرم افزاری، باید یک عمل را مناسب محیط انتخاب کنند تا پاداش بهینه بیشینه شود. این رشته به دلیل کلی بودن ، در بسیاری از رشته های دیگر از جمله نظریه بازی ، تئوری کنترل ، تحقیق در عملیات ، تئوری اطلاعات ، بهینه سازی مبتنی بر شبیه سازی ، سیستم های چند عامل ، هوشمند جمعی، آمار و الگوریتم های ژنتیکی مورد مطالعه قرار می گیرد. در یادگیری ماشین ، محیط به طور معمول به عنوان یک فرآیند تصمیم گیری مارکوف (MDP) معرفی می شود. بسیاری از الگوریتم های یادگیری تقویتی از تکنیک های برنامه نویسی پویا استفاده می کنند. در الگوریتم های یادگیری تقویتی ، فرضیه مبتنی بر دانش یک مدل دقیق ریاضی از MDP نیست ، و هنگامی که مدل های دقیق غیرقابل دسترسی هستند مورد استفاده قرار می گیرد. الگوریتم های یادگیری تقویتی در وسایل نقلیه خودران یا در یادگیری بازی در برابر حریف انسانی استفاده می شود.
یادگیری دیکشنری پراکنده
انجام پروژه متلب یادگیری دیکشنری پراکنده یا فرهنگ لغت پراکنده یک روش یادگیری ویژگی است که در آن یک مثال آموزشی به عنوان ترکیبی خطی از توابع پایه ارائه می شود ، و فرض بر این است که یک ماتریس پراکنده است. این مساله از نوع به شدت سخت NP-hard است و حل تقریبی آن دشوار است. الگوریتم K-SVD یک روش اکتشافی معمول برای یادگیری دیکشنری پراکنده است. یادگیری دیکشنری پراکنده در چندین زمینه استفاده شده است. در دسته بندی ، مسئله مشخص کردن کلاسهایی است که قبلا دیده نشده اند متعلق به نمونه آموزشی اند. برای دیکشنری که در آن هر کلاس از قبل ساخته شده است ، یک مثال آموزشی جدید با کلاس همراه است که به بهترین شکل توسط دیکشنری مربوطه نمایش داده می شود. مثلا یادگیری دیکشنری پراکنده در تشخیص و جداسازی نویز تصویر استفاده شده است. ایده اصلی این است که تکه های تصویر تمیز و بدون نویز می تواند جداگانه توسط یک دیکشنری تصویری نشان داده شود ، اما قسمت نویز نمی تواند.
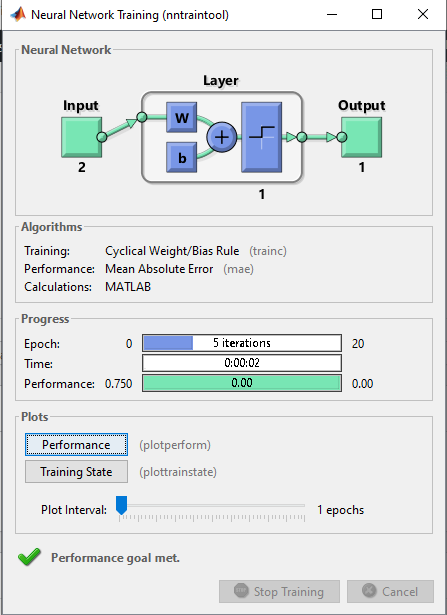
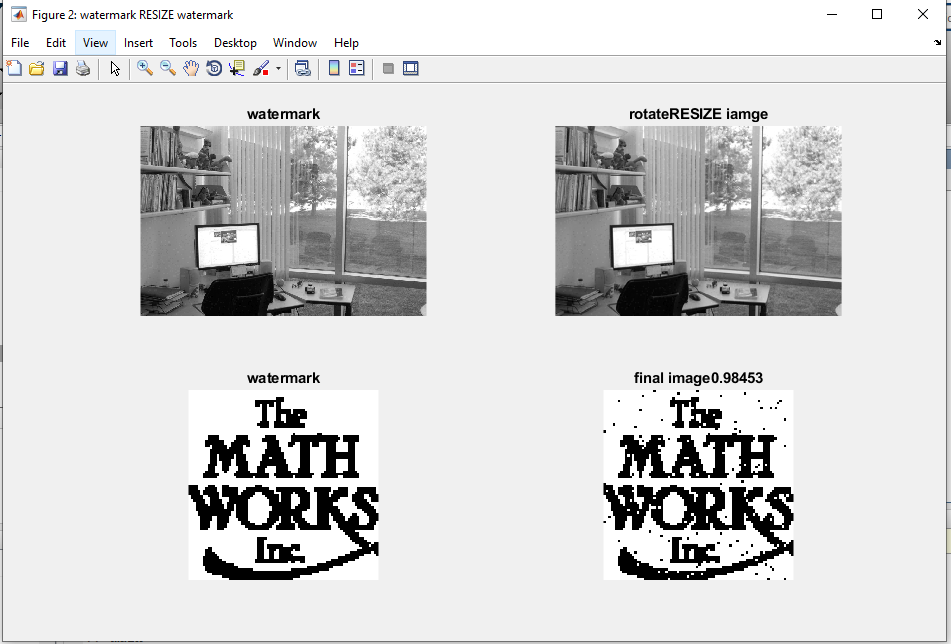
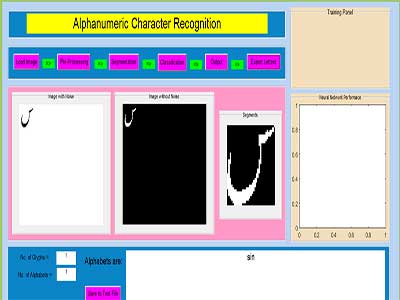
خروجی متلب :



لطفاً براي ارسال دیدگاه، ابتدا وارد حساب كاربري خود بشويد