پروژه OCR با شبکه عصبی و شبیه سازی در نرم افزار MATLAB
فروش پروژه OCR با شبکه عصبی و شبیه سازی در نرم افزار MATLAB:متلب پروژه
متلب پروژه : شبیه سازی خواندن و تشخیص متن توسط ماشین به ۲ گروه کلی تقسیم می شود :
- جمع آوری اطلاعات برای تشخیص :
الف. Offline : شامل تصاویری است که از نوشته ها تهیه می شود . مانند عکس توسط دوربین دیجیتالی ، اسکن نامه ها و صفحه های کتاب و از این دست تصاویر .
ب. Online : در این مدل تشخیص متن ، همزمان با نوشتن آن ، متن ِ نوشته شده تشخیص داده شده و تبدیل به کاراکترهای آن می شود . مانند تشخیص دست خط در handled ها و یا در TabletPC ها .
۲٫ نوع متن
الف. دست نویس
ب. متن تایپ شده که توسط ماشین چاپ شده است ، مانند کتابها ، مجلات و …
متلب پروژه : عملیات تشخیص متن عموما ً شامل مراحل زیر است :
- پیش پردازش : شامل روش های مختلف پردازش تصویر است که تصویری بدون نویز و مناسب برای قطعه بندی را آماده می کند .
- قطعه بندی : مهمترین و مشکلترین کاری که برای تشخیص متن باید انجام شود قطعه بندی تصویر به قطعاتی است که توسط قسمت تشخیص متن باید به کاراکتر یا کلمه تفسیر شود . قطعه بندی اشتباه تصویر منجر به تفسیری اشتباه از کاراکتر نقاشی شده در آن می شود . انواع قطعه بندی به شرح زیر است :
الف. External Segmentation : هدف در این نوع قطعه بندی جدا کردن اجزای کلی متن مانند پاراگراف و سطرها می باشد . امکان برچسب زنی بر روی اجزای صفحه ، مانند عنوان یا چکیده نیز در این نوع قطعه بندی می تواند وجود داشته باشد .
ب. Internal Segmentation : برای جدا کردن کاراکترها از یکدیگر استفاده می شود .
یک. Implicit segmentation : تشخیص کاراکترها با توجه به معانی که از قطعات جدا شده قابل تفسیر است صورت می گیرد .
دو. Explicit Segmentation : جدا کردن کاراکترها با توجه مشخصه هایی که برای آنها قابل تصور است . مثلا ً horizontal projection که از روی قله ها یا دره ها در هیستوگرام افقی یا عمودی سطر، کلمه یا حرف را پیدا می کند . - آموزش و تشخیص کاراکترها : بعد از قطعه بندی ، تصویر قطعه قطعه شده می بایست توسط الگوریتمی به متن تفسیر شود . روشهای مختلفی برای این کار وجود دارد که هر کدام از آنها را می توان با دو دیدگاه اجرایی کرد. در دیدگاه اول قطعات تصویر حاوی “کلمه” های متن اصلی هستند و الگوریتم باید کلمه ها را تشخیص دهد . در این دیدگاه دایره لغات کم خواهد بود ولی مشکل قطعه قطعه کردن تصویر کمتر است . برای تفسیر دست خط با توجه به تعدد روش نوشتن یک کلمه ، نرخ تفسیر کمتری از متن تایپی دارد . روش دوم روشهای analytic است که از پایین به بالا عمل کرده و سعی می کند کاراکترها را شناسایی کرده و با ترکیب آنها لغت ها را بسازد . در عمل از ترکیب روشهای زیر استفاده می شود :
الف. Template Matching : تعدادی template از کاراکترها یا کلمات از قبل حاضر شده است . عکسهای قطعه قطعه شده با این template ها مقایسه می شود و با توجه به شباهت برنده انتخاب می شود .
ب. متلب پروژه : روشهای آماری : با استفاده از برخی مشخصه های آماری و توابع تصمیم گیری آماری کار تشخیص نوع هر کدام از تصاویر قطعه قطعه شده را انجام می دهد . روشهای non-paramteric ، parametric ، cluster analysis و hidden markov modeling از انواع این روش است .
پ. روشهای ساختاری : با توجه به تعدادی الگوی پایه که از قبل تعریف شده است و میزان استفاده هر کدام از تصاویر از این الگوهای پایه عملیات تشخیص انجام می شود . Grammatical methods و graphical methods از انواع این روشها می باشد .
ت. شبکه های عصبی : با توجه به خاصیت شبکه های عصبی که قابلیت تطبیق پذیری با اطلاعات جدید و مختلف را در حد بالایی دارند ، از آنها برای تشخیص استفاده می شود . - متلب پروژه : پس پردازش : بعد از بدست آوردن متن از تصویر می توان آنها را با توجه به اطلاعاتی که درباره آن عکس داریم تصحیح کرد. مثلا ً با توجه به موضوع متن ، لغت هایی که احتمالا ً اشتباهی جزو متن تشخیص داده شده را حذف یا تصحیح کرد . استفاده از لغت نامه نیز یکی از ابزارهایی است که در این مرحله قابل استفاده می باشد .
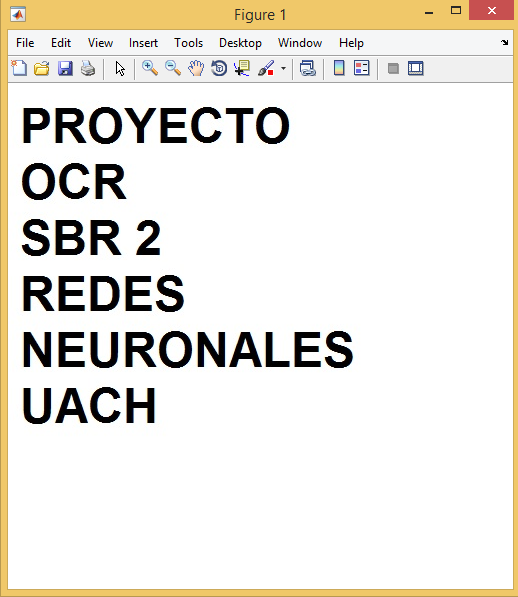
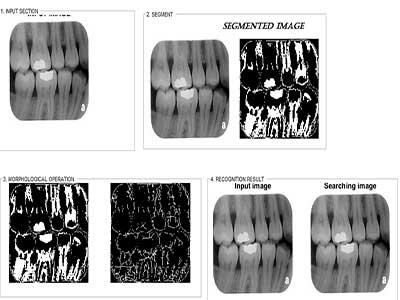
تصویر خروجی برنامه :

لطفاً براي ارسال دیدگاه، ابتدا وارد حساب كاربري خود بشويد