دسته بندی داده های باینری بوسیله الگوریتم های ga و pso و fa و iwo
دسته بندی داده های باینری بوسیله الگوریتم های ga و pso و fa و iwo :انجام پروژه متلب
دسته بندی داده های آماری و جدول فراوانی
انجام پروژه متلب:در داده های آماری دسته بندی نشده به تعداد دفعاتی که هر داده تکرار می شود فراوانی مطلق آن داده گفته می شود و آن را با fi نشان می دهند.

انجام پروژه متلب:
فراوانی نسبی: نسبت فراوانی مطلق هر داده به تعداد کل داده ها، فراوانی نسبی نامیده می شود.
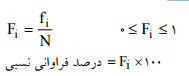
دسته بندی داده های آماری
اگر تعداد داده ها کم باشد یا داده ها خیلی پراکنده و دارای توزیع وسیع نباشند، جدولی متشکل از داده و تعداد تکرار آنها رسم می کنیم که به آن جدول توزیع فراوانی گفته می شود.
دامنه داده ها
انجام پروژه متلب:فاصله کمترین داده از بیشترین داده در یک جامعه ی آماری، دامنه جامعه آماری نامیده شود و آن را با Rنشان می دهند.R=Xmax-Xmin
حدود دسته ها
هر دسته به صورت یه بازه به شکل [a,b) نمایش داده می شود که در آن a کران پایین دسته و b کران بالای دسته نامیده می شود.
نکته: برای دستور خاصی برای انتخاب تعداد دسته ها وجود ندارد، اما معمولاً تعداد دسته ها را به گونه ای انتخاب می کنند که فراوانی هیچ دسته ای صفر نشود.
طول دسته
تفاضل کران پایین هر دسته از کران بالای آن طول دسته می باشد(C=b-a) که در کتاب آمار دبیرستان معمولاً طول تمام دسته ها برابر فرض می شود. اگر طول C دسته وK تعداد دسته ها باشد رابطه زیر را داریم:
مرکز دسته
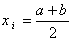
فراوانی یک دسته در داده های دسته بندی شده
تعداد داده هایی که در هر دسته قرار می گیرند را فراوانی مطلق آن دسته می گویند.
فراوانی نسبی
فراوانی نسبی دسته iام در داده های دسته بندی شده برابر است با:
فراوانی تجمعی
نکته: اختلاف دو فراوانی تجمعی نسبی برابر است با فراوانی مطلق اندیس بالاتر. F ci+1 -Fci=f ci+1
مثال: توزیع زیررا در نظر می گیریم، درصد فراوانی نسبی متناظر با ۵ = xi کدام است؟
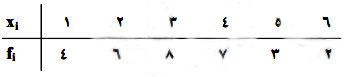
پاسخ: طبق فرمول فراوانی نسبی داریم:
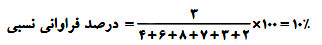
شاخص های مرکزی داده های آماری
شاخص های مرکزی عبارتند از: میانگین، میانه، مد .
میانگین: میانگین n داده آماری x1,x2,….xn برابر است با:
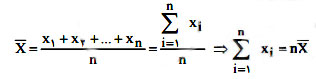
در یک جامعه آماری، میانگین عددی منحصر به فرد است که همواره بین بزرگ ترین داده و کوچکترین داده قرار دارد.
محاسبه میانگین در جدول فراوانی: (میانگین وزن دار)
میانگین n داده ی آماری که در آن داده ها دارای فراوانی باشند برابر است با
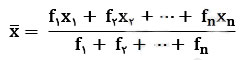
میانه
اگر داده های آماری را به صورت صعودی یا نزولی مرتب کنیم، در صورتی که تعداد داده ها فرد باشد، عددی که در وسط قرار
می گیرد و اگر تعداد داده ها زوج باشد، نصف مجموع دو عددی که در وسط قرار گرفته، میانه نام دارد. معمولاً میانه مقداری است که تعداد اعضایی از جامعه که از آن بیشترند برابر تعداد اعضایی است که از آن کمترند.
مثال: میانه داده های زیر را بدست آورید:
۵ ،۹ ،۱۰ ،۱۴ ،۱۹ ،۱۷ ،۱۴ ،۱۵ ،۱۷ ،۱۱ ،۱۲ ،۳ ،۷ ،۷ ،۴
پاسخ: ابتدا داده ها را مرتب می کنیم.
۳ ۴ ۵ ۷ ۷ ۹ ۱۰ ۱۱ ۱۲ ۱۴ ۱۴ ۱۵ ۱۷ ۱۹
چون ۱۵داده داریم، داده ۸ ام میانه است. پس عدد ۱۱ میانه است.
مد یا نما
مقدار یا مقادیری از متغیر که در آنها فراوانی ماکزیمم مطلق باشد، مد نامیده می شود. در واقع مد دادهای است که بیشترین تکرار را در میان داده ها داشته باشد و توجه کنید که مد منحصر به فرد نیست.
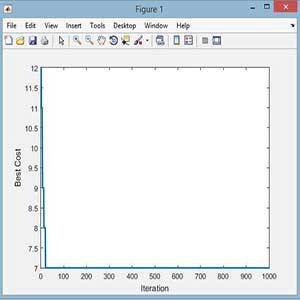
خروجی متلب :
الگوریتم pso ، iwo:
Iteration 996: Best Cost = 7
Iteration 997: Best Cost = 7
Iteration 998: Best Cost = 7
Iteration 999: Best Cost = 7
Iteration 1000: Best Cost = 7
الگوریتم ga :
Iteration 995: Best Cost = 7
Iteration 996: Best Cost = 7
Iteration 997: Best Cost = 7
Iteration 998: Best Cost = 7
Iteration 999: Best Cost = 7
Iteration 1000: Best Cost = 7


لطفاً براي ارسال دیدگاه، ابتدا وارد حساب كاربري خود بشويد